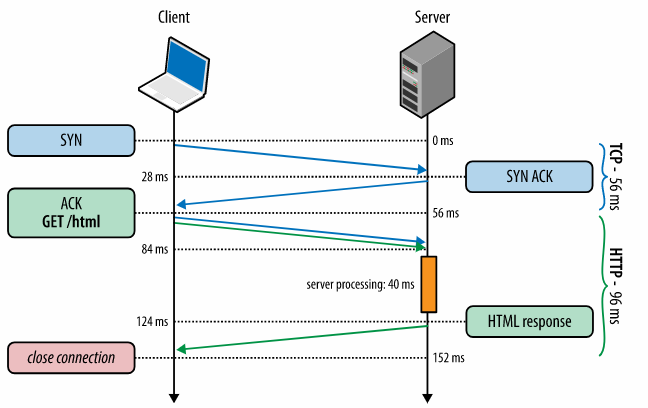
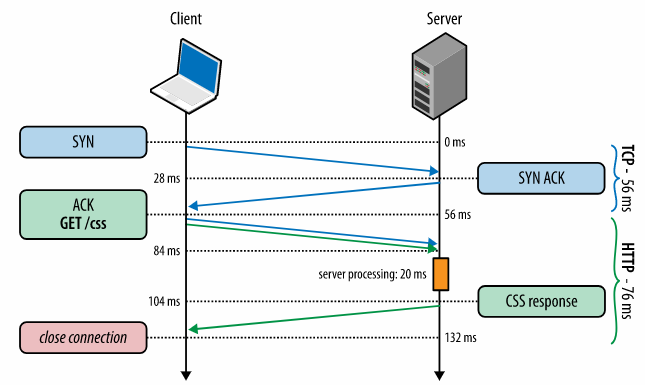
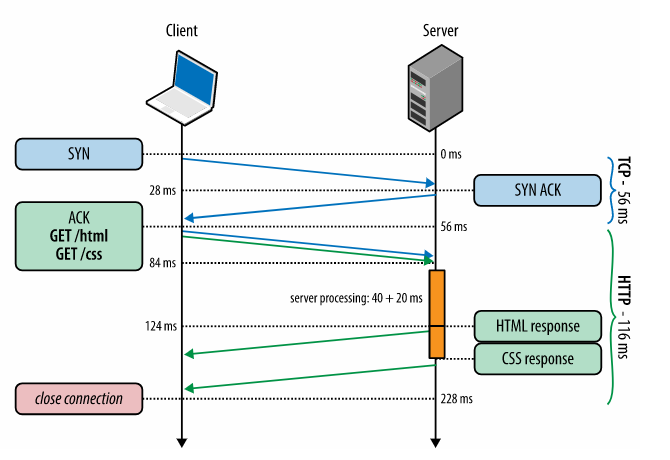
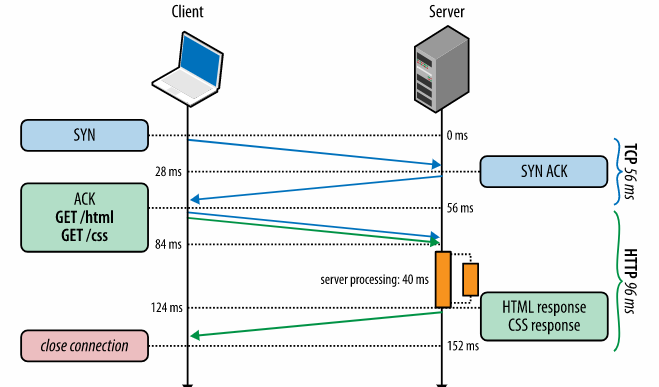
由于公司的培养计划,今年8月中旬我rotate到了一个新的团队,新团队的老大找了4个人(包括我)决定做一个辅助trader分析决策的系统,一些指标的图表显示,相似度推荐和预测(涉及到业务,不能多说)。花了一个月进行机器学习的知识储备和需求分析后,开始了短暂的架构之旅。
系统划分
在设计一个完整的系统的时候,需要将其拆分成多层,每层系统独立完成一个功能,之间不会有影响,可以独立进行技术选型和架构设计,各层之间用rpc,restful,或者消息中间件来通信,符合高内聚低耦合的特点。
在进行各层技术选型时,按序考虑如下:
- 符合公司政策
- 适用于业务
- 社区活跃(文档完整)
- 学习难度与团队成员熟悉程度
我们将系统核心拆分成了4层:数据处理层,模型训练层,模型接口服务提供层,数据服务层。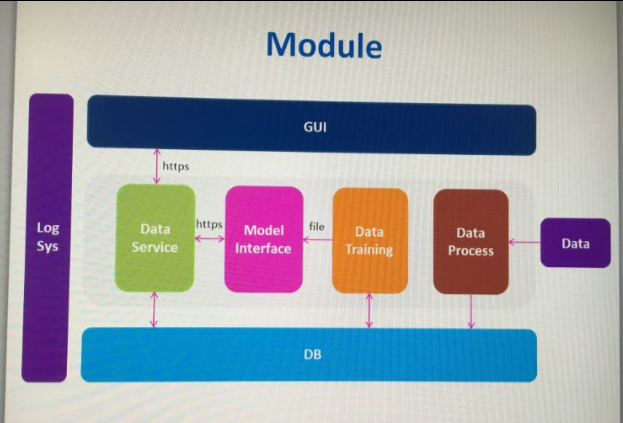
数据处理层
我们系统的数据都是从上游系统来的,什么形式现在还没正式确定(可以和上游系统商议),公司内部最常用的形式是文件feed,。在这里,进行数据转换工作,我们把数据主要分为两部分,一部分是用于指标显示的(股票前10天的均价,客户成交额等等),存于DB。另一部分用于模型训练,这部分数据可能存DB也可能存为文件格式。
技术选型: spring batch vs spark streaming。
- spring batch: 企业批处理框架,公司内部常用,但不支持实时,可以用来做伪实时,定时(每小时)调度job,不支持分布式,无法支持大量的数据
- spark streaming: 分布式实时运算框架,支持海量数据,准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理。处于spark生态区,与其类似的是storm,一个纯实时的框架。
因为本系统每日的数据量不到百万,所以暂时用spring batch来做伪实时的数据处理。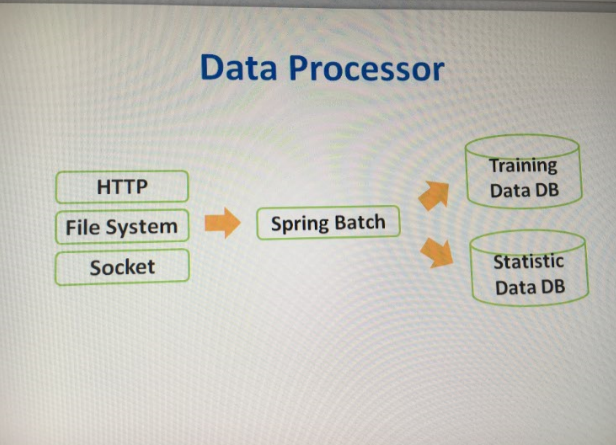
模型训练层
在系统上线前我们会通过数据预处理->特征提取->模型训练->测试的反复迭代训练好模型,在这里会采用online learning的算法,训练好的模型存为文件(方便以后的还原),并且将选好的特征存到数据库中,这样日常新来的数据就可以直接进行过滤转换了。每隔一段较长时间会重新进行特征的选取。
难点:产品上线后模型的准确度测试方法还没想到
技术选型: sklearn vs tensorflow vs mllib
- sklearn:上手简单,不支持分布式,传统式机器学习库,文档全,比较适合学习
- tensorflow: google的深度学习框架,支持分布式,文档全
- mllib: spark生态圈的,支持分布式,但库很少
我们的历史数据达到亿条记录,并且tensorflow前景个人感觉很好,所以就用它了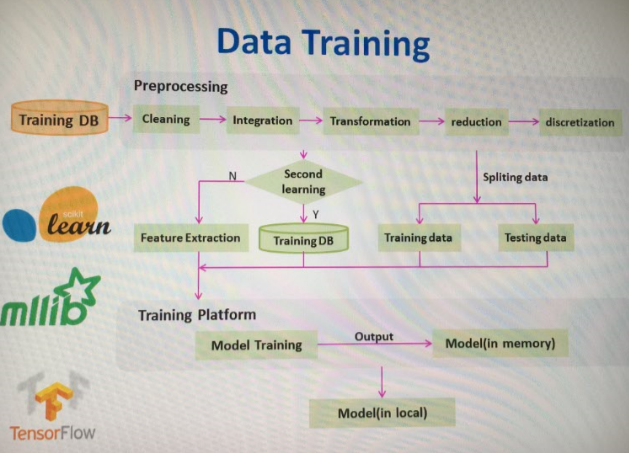
模型接口服务提供层
这里会用python flask起一个web server去还原tensorflow的模型,并且接受数据服务层的请求来进行模型的调用(预测,相似度判断等)。
这是最尴尬的一层,因为我实在没找到除了用python调用tensorflow api以外其它还原模型的方法。如果是以脚本的形式,比如在node中调用一段python代码去调用模型,那么每一个request过来,都得去还原模型一次,这显然是不行的,换成http server的话,可以将其缓存在内存中,只有当模型更新的时候才会去重新还原一次模型。
数据服务提供层
这里接受gui的请求,从数据库中去拿数据或者调用模型接口服务。因为这层基本没有逻辑和计算操作,大部分为数据库io操作,所以我们采用node。
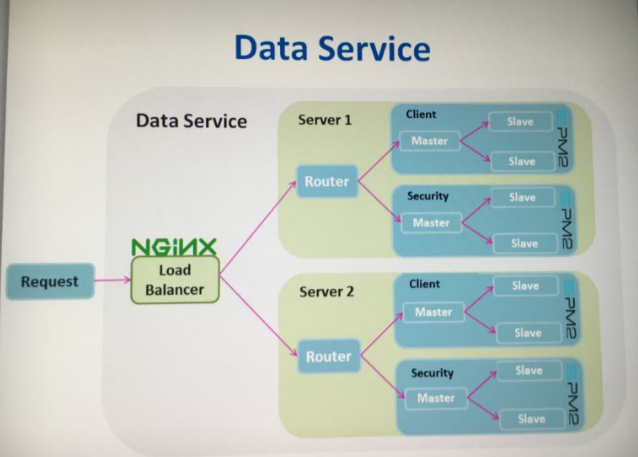
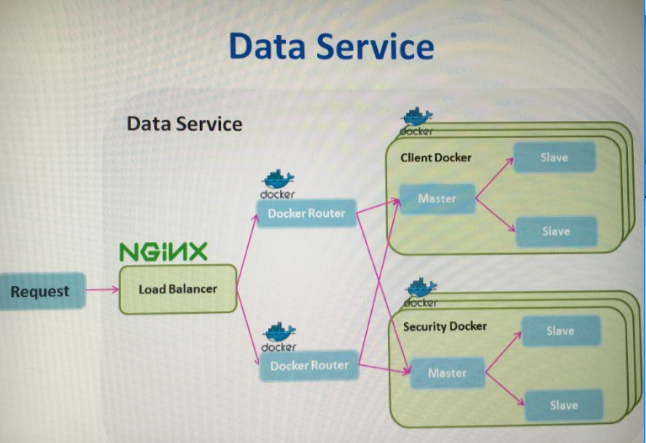
我们在这层采用微服务的思想(关于微服务的讨论见:https://www.zhihu.com/question/37808426),由于我们的系统主要包含两部分信息client(客户)和security(证券),两部分信息的显示内容以及用户可进行的操作是不同的,所以将security和client各独立成一个service进程,gui的请求会发送到router上,api router根据url的匹配将请求转发给client和security service。以后扩展,可以在router前个ngnix load balancer, 在service上用pm2管理,实现一个master worker的load balance,甚至还可以引入docker。
关于token验证,如果只在gateway router上做权限认证的话,那么便无需登录可以直接访问service api了,所以要在service上做权限认证。这里会涉及到一个token共享的问题,因为每个service是独立的进程,不会共享资源,现在是存数据库,每个service都会维护一个token的list,一个request到了以后,判断是否存在内存,不存在就去数据库比较,数据库有并且这个token是有效的就添加入这个list,以后会调用公司的权限认证服务,它可以判断该token是否仍有效。这样每个service都会维护着同一份token list了。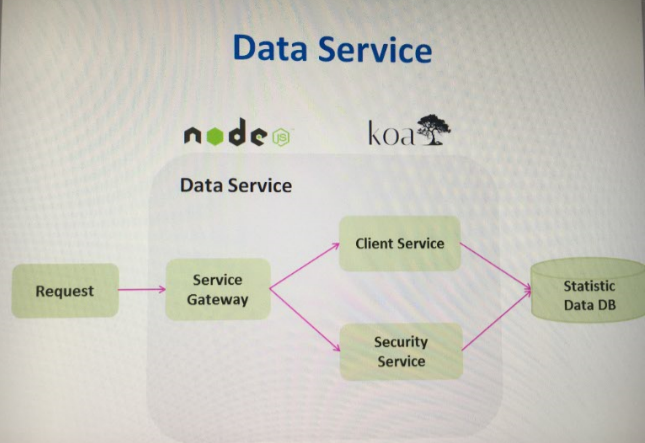
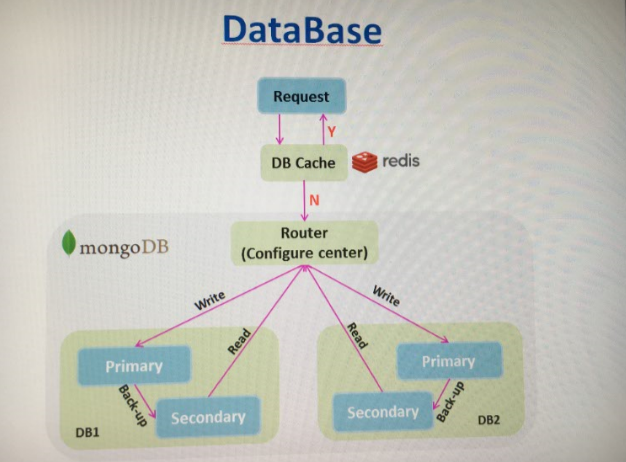
数据库
数据库我们采用的是mongo,这个系统不需要事务的回滚,而且对数据量的存储以及读取性能有一定要求,mongo本身就支持集群,关于关系型数据库以及非关系数据库之间的比较太多,不赘述。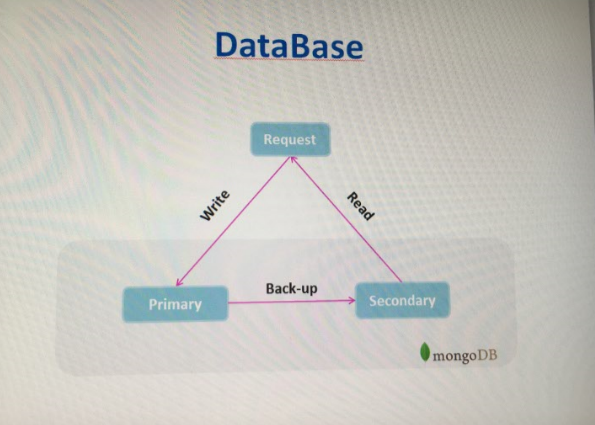
GUI
这系统类似一个图表系统,感觉什么框架都行,本来我们想用react的,然后在搭建的时候react出了license的问题,因为公司的policy(系统代码永远不对外公开),就转为angular了,而且我们还有人对angular较熟悉,所以license问题解决了,我们也没改变。
POC阶段
为了快速立项,所以POC阶段追求简单,我们会直接把数据mock进数据库。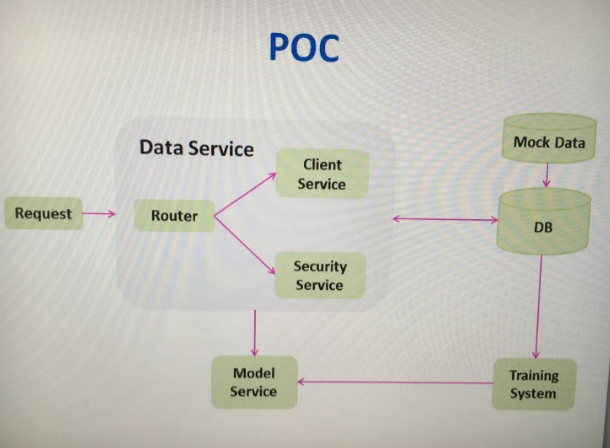
后续
目前刚把router以及两个service公用的私有npm包写完,以上只是对这个系统的构想,后续在实践中还会不断更正,而且我现在还挺菜的,所以肯定有很多不完善的地方,尤其在机器学习那块,经验几乎为0,就靠一个月的强化学习。肯定有很多不足,但纪念自己的第一次真正有意义架构。
参考资料: